[Before you start reading, I need to give a big thanks to Christian Esteve Rothenberg, Research Scientist at CPqD. I asked if he wouldn't mind reading through this post prior to posting to ensure I didn't botch up anything on RouteFlow, and sure enough he immediately helped out and provided great feedback. Christian also provided us with the picture you'll eventually see below and many of the RouteFlow links as well. There was much more information he provided that I'll hope to get out soon too. Thanks again, Christian.]
So...let's get to it.
Understanding “flow based protocols” and RouteFlow can change the way you think about networking and the protocols we use on daily basis. I’m referring to control plane protocols such as Spanning Tree, OSPF, EIGRP, and BGP. Based on the traction from this blog, I can see many people are searching for answers on what SDN means for the industry and what the future will be for a network engineer, etc. If you are one of those people, first, ready my last post. It’s a quick synopsis of a presentation at ONS that covers some interesting automated tools already available for controller based networks. And second, keep reading here.
So...let's get to it.
Understanding “flow based protocols” and RouteFlow can change the way you think about networking and the protocols we use on daily basis. I’m referring to control plane protocols such as Spanning Tree, OSPF, EIGRP, and BGP. Based on the traction from this blog, I can see many people are searching for answers on what SDN means for the industry and what the future will be for a network engineer, etc. If you are one of those people, first, ready my last post. It’s a quick synopsis of a presentation at ONS that covers some interesting automated tools already available for controller based networks. And second, keep reading here.
In a recent SDN conversation, I was asked a few questions about protocols (OSPF, BGP, EIGRP, etc.). Will they still be around in a few years? Will they just go away with SDNs? Do we need them in networks that have a centralized control plane? Those are great questions and are what I’d like to cover in this post by visiting the subjects of flow-based protocols and RouteFlow.
Since others have covered these topics already indirectly and directly, I’m going to provide an overview of each, and then provide links to other pages and documents that go into far greater detail.
Flow Based Protocols
We know about Layer 2 and Layer 3 control plane protocols. So what is a flow based protocol? Instead of thinking about Layer 2 and Layer 3 independently, try thinking about them together in a unified fashion, and then ask yourself, “Why should network traffic be limited to pre-defined paths? Why should all traffic primarily follow the same path and be largely based on destination IP PREFIX? Could there be a different way?” After all, if you ask an application guy or gal about their network requirements, they probably wouldn’t talk about destination IP PREFIXES. Why can’t applications just have the ability to demand their associated network requirements so flows are built accordingly and auto-magically?
Flow Based Protocols allow you to build network or flow forwarding policies based on source physical port, source/destination MAC Address, VLAN ID, source/destination IP Address, and associated L4 information (port/protocol). Other information can be used, but for now, we are just using MAC, IP, VLAN, and L4 info, for this discussion. Think of this as Policy Based Routing (PBR) on steroids. Configure a set of match conditions (source port and MAC) and configure an action (forward to Port 5). Simple. Large networks with lots of PBR deployed can be difficult to manage, so the value add with what is being discussed here with SDN flow based protocols, is that they will be centrally and easily managed with a network based (SDN) controller (that’s the hope anyway!). This SDN controller would have a central view of the network. As an administrator, one can develop or use policies based on destination prefix should one want to maintain similar functionality as to what is deployed today with a routing protocol such as OSPF, or one can deploy fine-tuned policies that are very specific for certain hosts/applications by combining L2-L4 to develop a flow forwarding policy. These fine-tuned policies would *route* traffic based on anything you’d like. Since *route* is usually analogous to L3 and information at L2 and L4+ are being used to calculate flows, that is why we are using the term “flow protocols” rather than “routing protocols.”
Once a topology is calculated, the flow information required to permit or deny flows would be written directly into hardware (FIB) on the switch. Just to recap, in this example, the switch would not be running L2 and L3 control plane protocols as we know them today. The SDN controller has a physical view of the network (via some other means) and because of this, it is able to compute flows, translate them into FIB entries (e.g. OpenFlow table entries), and send them (e.g. via OpenFlow protocol) to the appropriate switches that need those entries. Remember, these are NEW ideas that are largely part of OpenFlow and SDN conversations. But, it is because of this type of functionality…to be able to automatically and/or manually program the state of the network, the protocols we see on a LAN and within the Data Center in the future will likely be far different than what they are today. While protocols like OSPF have lots bells and whistles you can turn on and off for large scale routed environments, a protocol like that can probably be stripped down and simplified for the mid-tier to Enterprise networking environment. After all, what we are really looking for is a simple way to calculate primary and backup paths (per flow or application) and to have the ability to dynamically give the applications the network resources they need. REPEAT: Why can’t applications just have the ability to demand their associated network requirements so flows are built accordingly and auto-magically? Maybe that is asking for too much – we still need jobs, don’t we? ;)
On a side note, think about Layer 2 vs. Layer 3 in the concept of flow based protocols. Where do default gateways reside? Do we need them? Really think about a flow and then what happens at L2 and L3. At Layer 3 in an Ethernet environment, the router is re-writing source/dest MAC addresses. Remember, source IP and dest IP does not change. Example: a source can be MAC A in VLAN A with IP 1.1.1.1 and a destination can be some host in a different VLAN on a different subnet, but on the same physical switch. Normally, network goes through the process of ARP, data transmission, default gateway is hit, L2 re-write aka L3, etc. ARP again, etc.
But, in a flow based network, a flow can be defined on that switch that permits host A to communicate with host B natively on that switch. Really? Yep, with a little bit of trickery and MAC/VLAN re-writes. Layer 2 and Layer 3 as we know them today could be gone. That trickery is all about flows and manipulating the network traffic appropriately with an intelligent controller. In this type of scenario, based on who is manufacturing the switch and/or controller, it will be very important to always ask and understand who is responding to ARP requests and who is the default gateway.
Recently having a watched a demo by NEC, their response to this for their solution was ARP responses come from the controller, but the default gateway exists everywhere, but nowhere. I love that statement. It really gets you thinking. The controller can ensure any two hosts can or cannot communicate with defined flows no matter the logical or physical design. While we probably won’t NEED default gateways in the future, they probably aren’t going away anytime soon. We need some way of staying sane, don’t we?
I’ve stated the word ‘flow’ quite a bit already when referring to the communication between two hosts. Please note a flow can be an aggregate flow as well if you have ways to summarize based on your traffic requirements. This can be done with wildcards as you normally would with routes or ACLs.
Interested in learning more about the future of Layer 2, Layer 3, and Flow Based Protocols? Check these links out for much more information. Big shout out to Greg, Ivan, and Dan for writing these over the last year or so!
Defining Flow Forwarding Instead of Switch or Routing - by Greg Ferro
OpenFlow and Software Defined Networking: Is it Routing or Switching? - by Greg Ferro
Building a Scalable OpenFlow Network with MAC Based Routing - by Dan Hersey
Controller Based Networks for Data Centres - by Greg Ferro
OpenFlow and Software Defined Networking (webinar) – may need subscription to view - by Greg Ferro and Ivan Pepelnjak
What is OpenFlow? --- oldie, but goodie -- by Ivan Pepelnjak
And feel free to check my archives for “OpenFlow or “SDN” related blogs.
Since others have covered these topics already indirectly and directly, I’m going to provide an overview of each, and then provide links to other pages and documents that go into far greater detail.
Flow Based Protocols
We know about Layer 2 and Layer 3 control plane protocols. So what is a flow based protocol? Instead of thinking about Layer 2 and Layer 3 independently, try thinking about them together in a unified fashion, and then ask yourself, “Why should network traffic be limited to pre-defined paths? Why should all traffic primarily follow the same path and be largely based on destination IP PREFIX? Could there be a different way?” After all, if you ask an application guy or gal about their network requirements, they probably wouldn’t talk about destination IP PREFIXES. Why can’t applications just have the ability to demand their associated network requirements so flows are built accordingly and auto-magically?
Flow Based Protocols allow you to build network or flow forwarding policies based on source physical port, source/destination MAC Address, VLAN ID, source/destination IP Address, and associated L4 information (port/protocol). Other information can be used, but for now, we are just using MAC, IP, VLAN, and L4 info, for this discussion. Think of this as Policy Based Routing (PBR) on steroids. Configure a set of match conditions (source port and MAC) and configure an action (forward to Port 5). Simple. Large networks with lots of PBR deployed can be difficult to manage, so the value add with what is being discussed here with SDN flow based protocols, is that they will be centrally and easily managed with a network based (SDN) controller (that’s the hope anyway!). This SDN controller would have a central view of the network. As an administrator, one can develop or use policies based on destination prefix should one want to maintain similar functionality as to what is deployed today with a routing protocol such as OSPF, or one can deploy fine-tuned policies that are very specific for certain hosts/applications by combining L2-L4 to develop a flow forwarding policy. These fine-tuned policies would *route* traffic based on anything you’d like. Since *route* is usually analogous to L3 and information at L2 and L4+ are being used to calculate flows, that is why we are using the term “flow protocols” rather than “routing protocols.”
Once a topology is calculated, the flow information required to permit or deny flows would be written directly into hardware (FIB) on the switch. Just to recap, in this example, the switch would not be running L2 and L3 control plane protocols as we know them today. The SDN controller has a physical view of the network (via some other means) and because of this, it is able to compute flows, translate them into FIB entries (e.g. OpenFlow table entries), and send them (e.g. via OpenFlow protocol) to the appropriate switches that need those entries. Remember, these are NEW ideas that are largely part of OpenFlow and SDN conversations. But, it is because of this type of functionality…to be able to automatically and/or manually program the state of the network, the protocols we see on a LAN and within the Data Center in the future will likely be far different than what they are today. While protocols like OSPF have lots bells and whistles you can turn on and off for large scale routed environments, a protocol like that can probably be stripped down and simplified for the mid-tier to Enterprise networking environment. After all, what we are really looking for is a simple way to calculate primary and backup paths (per flow or application) and to have the ability to dynamically give the applications the network resources they need. REPEAT: Why can’t applications just have the ability to demand their associated network requirements so flows are built accordingly and auto-magically? Maybe that is asking for too much – we still need jobs, don’t we? ;)
On a side note, think about Layer 2 vs. Layer 3 in the concept of flow based protocols. Where do default gateways reside? Do we need them? Really think about a flow and then what happens at L2 and L3. At Layer 3 in an Ethernet environment, the router is re-writing source/dest MAC addresses. Remember, source IP and dest IP does not change. Example: a source can be MAC A in VLAN A with IP 1.1.1.1 and a destination can be some host in a different VLAN on a different subnet, but on the same physical switch. Normally, network goes through the process of ARP, data transmission, default gateway is hit, L2 re-write aka L3, etc. ARP again, etc.
But, in a flow based network, a flow can be defined on that switch that permits host A to communicate with host B natively on that switch. Really? Yep, with a little bit of trickery and MAC/VLAN re-writes. Layer 2 and Layer 3 as we know them today could be gone. That trickery is all about flows and manipulating the network traffic appropriately with an intelligent controller. In this type of scenario, based on who is manufacturing the switch and/or controller, it will be very important to always ask and understand who is responding to ARP requests and who is the default gateway.
Recently having a watched a demo by NEC, their response to this for their solution was ARP responses come from the controller, but the default gateway exists everywhere, but nowhere. I love that statement. It really gets you thinking. The controller can ensure any two hosts can or cannot communicate with defined flows no matter the logical or physical design. While we probably won’t NEED default gateways in the future, they probably aren’t going away anytime soon. We need some way of staying sane, don’t we?
I’ve stated the word ‘flow’ quite a bit already when referring to the communication between two hosts. Please note a flow can be an aggregate flow as well if you have ways to summarize based on your traffic requirements. This can be done with wildcards as you normally would with routes or ACLs.
Interested in learning more about the future of Layer 2, Layer 3, and Flow Based Protocols? Check these links out for much more information. Big shout out to Greg, Ivan, and Dan for writing these over the last year or so!
Defining Flow Forwarding Instead of Switch or Routing - by Greg Ferro
OpenFlow and Software Defined Networking: Is it Routing or Switching? - by Greg Ferro
Building a Scalable OpenFlow Network with MAC Based Routing - by Dan Hersey
Controller Based Networks for Data Centres - by Greg Ferro
OpenFlow and Software Defined Networking (webinar) – may need subscription to view - by Greg Ferro and Ivan Pepelnjak
What is OpenFlow? --- oldie, but goodie -- by Ivan Pepelnjak
And feel free to check my archives for “OpenFlow or “SDN” related blogs.
RouteFlow
I recently had the opportunity, while at the Open Networking Summit, to talk with the team at Indiana University and CPqD who shared a booth representing the RouteFlow project. CPqD is leading the charge on the overall RouteFlow development, while IU is heavily involved with ongoing testing and development of their own Web User Interface for RouteFlow. It’s as if Christian Esteve Rothenberg, Research Scientist at CPqD , seems to live and breathe RouteFlow, and for good measure too. In my opinion, RouteFlow or a commercialized version will be required as Software Defined Networks are deployed, but more importantly, as they are integrated with existing networks. With regards to flow based protocols, I stated above that, “…one can develop or use policies based on destination prefix should one want to maintain similar functionality as to what is deployed today with a routing protocol such as OSPF…” Well, what if you NEEDED OSPF in your new network, running with a centralized control plane running some special flow based protocols, in order to communicate with rest of the network. Or what if you were gradually migrating a current OSPF network (control plane per L3 node) to an SDN with a unified control plane? How does this happen? When you extract the control plane (or OSPF in this case) from the network node, how does it maintain connectivity with its neighbors that are still running OSPF? Mind boggling. This is where RouteFlow comes in.
RouteFlow, an application that would run north of your SDN controller, allows you to build a virtual network topology that runs on servers. Yep. That’s right – servers. For you network folk out there, make sure to branch out and do a little more systems work if you haven’t started already. With RouteFlow, you could build virtual routers that reside in Linux containers (LXC). From talking with Christian, I believe you can do a router per VM instead of LXCs, but most of their work is doing using containers. The virtual routers are running Quagga, an open source routing software suite. If you wanted to think about this as being on par with GNS3/Dynamips, I think that would be a fair comparison. But again, each router is in its own Linux container and instead of loading in a real IOS image to run, the routing protocols are using open source software, i.e. Quagga.
RouteFlow allows you to extract control planes as needed. You can deploy a 1:1 mapping of physical network nodes to virtual network nodes to get things started. However, as more of the network is deployed with RouteFlow, there may not be a need to maintain the 1:1 relationship. This is when new protocols will emerge – see flow-based protocols.
For a Greenfield environment fully based on new SDN concepts, OSPF may be non-existent, but as stated earlier, you may need to integrate that shiny new network with that old and legacy infrastructure that ONLY runs OSPF. Here you can create two virtual routers that map back to your two peering points in the network. Then, configure the two new SDN switches to punt all OSPF packets (matching protocol 89) to the controller (see picture below). This will allow the “old” routers to peer with the virtual routers. And from an SDN standpoint, OSPF calculates it’s paths just like it would normally (using Quagga) and translates the route calculations into flows, then inserts the proper flows into the FIB of the “new” devices while maintaining traditional OSPF adjacencies with the external routers running vendor-specific OSPF
I recently had the opportunity, while at the Open Networking Summit, to talk with the team at Indiana University and CPqD who shared a booth representing the RouteFlow project. CPqD is leading the charge on the overall RouteFlow development, while IU is heavily involved with ongoing testing and development of their own Web User Interface for RouteFlow. It’s as if Christian Esteve Rothenberg, Research Scientist at CPqD , seems to live and breathe RouteFlow, and for good measure too. In my opinion, RouteFlow or a commercialized version will be required as Software Defined Networks are deployed, but more importantly, as they are integrated with existing networks. With regards to flow based protocols, I stated above that, “…one can develop or use policies based on destination prefix should one want to maintain similar functionality as to what is deployed today with a routing protocol such as OSPF…” Well, what if you NEEDED OSPF in your new network, running with a centralized control plane running some special flow based protocols, in order to communicate with rest of the network. Or what if you were gradually migrating a current OSPF network (control plane per L3 node) to an SDN with a unified control plane? How does this happen? When you extract the control plane (or OSPF in this case) from the network node, how does it maintain connectivity with its neighbors that are still running OSPF? Mind boggling. This is where RouteFlow comes in.
RouteFlow, an application that would run north of your SDN controller, allows you to build a virtual network topology that runs on servers. Yep. That’s right – servers. For you network folk out there, make sure to branch out and do a little more systems work if you haven’t started already. With RouteFlow, you could build virtual routers that reside in Linux containers (LXC). From talking with Christian, I believe you can do a router per VM instead of LXCs, but most of their work is doing using containers. The virtual routers are running Quagga, an open source routing software suite. If you wanted to think about this as being on par with GNS3/Dynamips, I think that would be a fair comparison. But again, each router is in its own Linux container and instead of loading in a real IOS image to run, the routing protocols are using open source software, i.e. Quagga.
RouteFlow allows you to extract control planes as needed. You can deploy a 1:1 mapping of physical network nodes to virtual network nodes to get things started. However, as more of the network is deployed with RouteFlow, there may not be a need to maintain the 1:1 relationship. This is when new protocols will emerge – see flow-based protocols.
For a Greenfield environment fully based on new SDN concepts, OSPF may be non-existent, but as stated earlier, you may need to integrate that shiny new network with that old and legacy infrastructure that ONLY runs OSPF. Here you can create two virtual routers that map back to your two peering points in the network. Then, configure the two new SDN switches to punt all OSPF packets (matching protocol 89) to the controller (see picture below). This will allow the “old” routers to peer with the virtual routers. And from an SDN standpoint, OSPF calculates it’s paths just like it would normally (using Quagga) and translates the route calculations into flows, then inserts the proper flows into the FIB of the “new” devices while maintaining traditional OSPF adjacencies with the external routers running vendor-specific OSPF
Again, a great thanks to Christian from CPqD. He was able to provide the picture you see below from a working OpenFlow and RouteFlow environment. Notice the set of "Matches" and associated "Actions." In particular, you can clearly note all OSPF, ARP, RIP, ICMP, and BGP traffic are being sent out port 65533. In this case, port 65533 is a logical port that the OpenFlow controller is on. Pretty cool, eh?
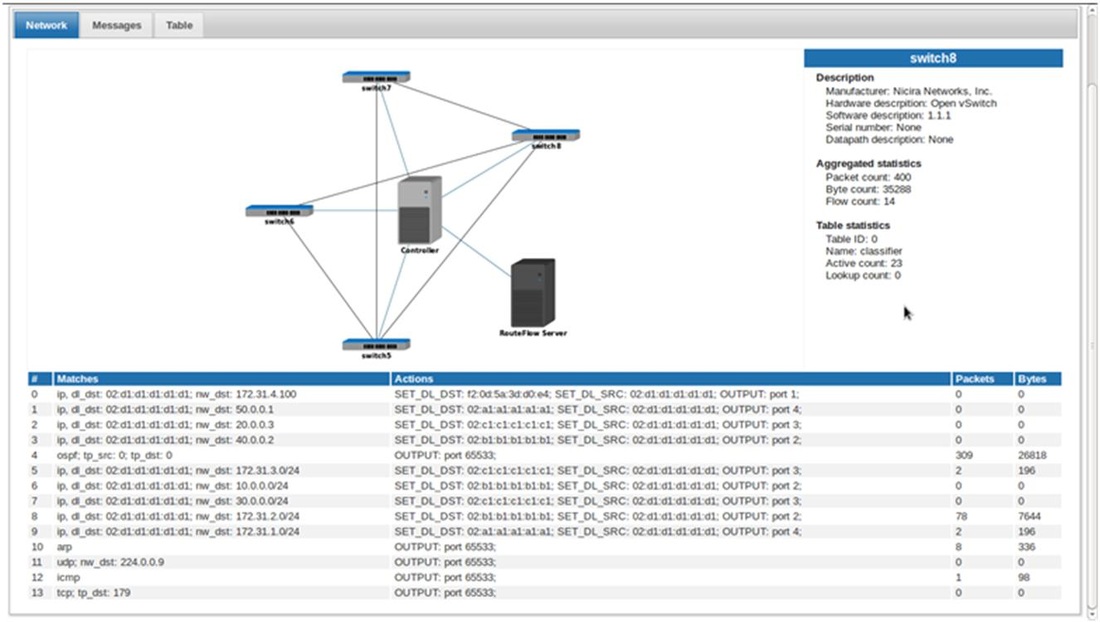
RouteFlow Picture - compliments of CPqD!
Note: Instead of matching OSPF packets by protocol number, this can also be accomplished by matching OSPF mcast addresses 224.0.0.5 & 2240.0.0.6. That’s actually how RouteFlow is implemented when using other protocols such as RIP. For BGP, the RouteFlow team matches on TCP port 179 (for security reasons we would extend the match with the IP source of the authorized neighbors IP addresses). This can also be noted above in the picture.
If this glue between IP routing protocols and OpenFlow has sparked your interest, you should take a look at the very detailed RouteFlow white papers that are available. See links below.
Official RouteFlow Documentation
RouteFlow Home RouteFlow Repository used by CPqD --- don't forget to check out the FAQ there too.
RouteFlow demo poster at ONS 2012 When protocols collide - by Google -- make sure to take a look at this one
Demo at SRS SuperComputing 2011 with switches from IBM, NEC and Pronto
Closing
The topics of flow protocols and RouteFlow are two of my favorites because you can directly look at Layer 2 and Layer 3 protocols as we know them today and see that the networks of the future may not be built the same way or with the same protocols we’ve been using for the past 20 years. It’s pretty amazing. What do you think?
Official RouteFlow Documentation
RouteFlow Home RouteFlow Repository used by CPqD --- don't forget to check out the FAQ there too.
RouteFlow demo poster at ONS 2012 When protocols collide - by Google -- make sure to take a look at this one
Demo at SRS SuperComputing 2011 with switches from IBM, NEC and Pronto
Closing
The topics of flow protocols and RouteFlow are two of my favorites because you can directly look at Layer 2 and Layer 3 protocols as we know them today and see that the networks of the future may not be built the same way or with the same protocols we’ve been using for the past 20 years. It’s pretty amazing. What do you think?
 RSS Feed
RSS Feed
